CQRS Design Pattern C#
CQRS design pattern in C# is a simple pattern that strictly segregates the responsibility of handling command input into an autonomous system from the responsibility of handling side-effect-free query/read access on the same system.
If you are familiar with Domain-Driven Design, you’ve most likely heard about, Command-Query Responsibility Segregation (CQRS). Though the CQRS pattern is well-known, there are still a lot of misconceptions around this pattern, especially when it comes to applying it in real-world software projects.
In this article, you will learn exactly what CQRS is, the principles behind it, and the benefits it can provide for your project.
We will see a detailed, step-by-step process of implementing this pattern in practice using a sample project we’ll be working on. This project will be close to what you can see in the real world, and I will explain each step on the way to implement CQRS design pattern in C#.
Contents
- Introduction
- Introducing a Sample Project
- Refactoring Towards a Task-based Interface
- Segregating Commands and Queries
- Implementing Decorators upon Command and Query Handlers
- Decorators vs. ASP.NET Middleware
- Simplifying the Read Model
- Conclusion
- When should I use CQRS?
- When should I avoid CQRS?
- Further Reading
- Books
- Online Courses
- Related Videos
- Frameworks
- References
Introduction
The idea behind the CQRS pattern is very simple. Instead of having one unified model, you need to introduce two: one for reads and the other one for writes, and that’s it.
CQRS was introduced by Greg Young back in 2010. Greg, himself, based this idea on the command-query separation principle coined by Bertrand Meyer.
When asked whether he considers CQRS to be an approach or a pattern, and if it’s a pattern, what problem it specifically solves, Greg Young answered:
“If we were to go by the definition that we set up for CQRS a number of years ago, it’s going to be a very simple low-level pattern. It’s not even that interesting as a pattern; it’s more just pretty conceptual stuff; you just separate. What’s more interesting about it is what it enables. It’s the enabling that the pattern provides that’s interesting. Everybody gets really caught up in systems and they talk about how complicated CQRS is with Service Bus and all the other stuff they are doing, and in actuality, none of that is necessary. If you go with the simplest possible definition, it would be a pattern. But it’s more what happens once you apply that pattern—the opportunities that you get.”
What is Command Query Separation principle
Command-query separation principle, CQS for short, states that every method should either be a command that performs an action, or a query that returns data to the caller, but not both.
To follow this principle, you need to make sure that if a method changes some piece of state, this method should always be of type void, otherwise, it should return something.
An example here is a List. Its Add method adds an element at the end of the list which can be considered as a command. Also, it has a Count method that returns the number of elements in the list that can be considered as the query.
1
2
3
4
5
6
7
8
9
10
11
List<string> dinosaurs = new List<string>();
dinosaurs.Add("Tyrannosaurus");
dinosaurs.Add("Amargasaurus");
dinosaurs.Add("Mamenchisaurus");
dinosaurs.Add("Deinonychus");
dinosaurs.Add("Compsognathus");
Console.WriteLine("Count: {0}", dinosaurs.Count());
//This code produces the following output.
//Count: 5
Exceptions to CQS principle
Although CQS provides some benefits you should remember that it is not always possible to follow the command-query separation principle.
And, there almost always will be situations where it would make more sense for a method to both have a side effect and return something.
An example here is Stack. Its Pop method removes the element pushed into the stack last and returns it to the caller.
1
2
3
4
5
6
7
8
9
10
11
12
// Creates and initializes a new Stack.
Stack myStack = new Stack();
myStack.Push( "The" );
myStack.Push( "quick" );
myStack.Push( "brown" );
myStack.Push( "fox" );
// Removes an element from the Stack.
Console.WriteLine( "(Pop)\t{0}", myStack.Pop() );
//This code produces the following output.
//(Pop) fox
This method violates the CQS principle, but at the same time, it doesn’t make a lot of sense to separate those responsibilities into two different functions.
Other examples include situations where the result of a query can become stale quickly, and so you have to join the query with the command.
For example, you have two methods, one for writing to a file, and the other one for ensuring that this file exists.
The problem with the idea is that the result of the query “if file exists” can become stale by the time the client code runs the file writing command. There could be some other process intervening right between these two calls, and it can delete the file after the query is called, and so to avoid this problem, we have to violate the command-query separation principle.
Other examples where the command-query separation principle is not applicable involve multi-threaded environments where you also need to ensure that the operation is atomic.
However, it’s still a good idea to make the CQS principle your default choice and depart from it only in exceptional cases, like those I described above.
Now,
What is CQRS?
CQRS takes the same idea of CQS and extends it to a higher level. Instead of methods like in CQS, CQRS focuses on the model and classes in that model and then applies the same principles to them.
Just like CQS encourages you to split a method into two, a command and a query, CQRS encourages you to untangle a single, unified domain model and create two models: one for handling commands or writes, and the other one for handling queries, reads.
The idea is extremely simple. However, it provides lots of benefits. Let’s see them next.
Benefits of CQRS
Scalability
If you look at a typical enterprise-level application, you may notice that among all operations: create, read, update, and delete, the one that is used the most is usually read.
There are disproportionately more reads than writes in a typical system, and so it’s important to be able to scale them independently from each other.
For example, you can host the command side on a single server, but create a cluster of 10 servers for the queries.
Performance
Even if you decide to host reads and writes on the same server, you can still apply optimization techniques that wouldn’t be possible with a single unified model.
For example, just having a separate set of APIs for the queries side allows you to set up a cache for that specific part of the application.
It also allows you to use database-specific features and hand-crafted, highly sophisticated SQL for reading data from the database.
At the same time, the command side of the application can use some kind of ORM like EF or NHibernate which is isolated from the query side.
Simplicity
CQRS provides simplicity, as you get two models after separating command and queries, each of which does only one thing, and does it well. You can view this as the single responsibility principle applied at the architectural level.
We can say that CQRS is about optimizing decisions for different situations. You can choose different levels of consistency, different database normal forms, and even different databases themselves for the command and query sides, all because you can think of commands and queries and approach them independently.
CQRS in the Real World
Let’s look at some examples from real-world projects.
If you ever used Entity Framework or NHibernate for writing data to the database, and raw SQL with plain ADO. NET for reading it back, that was CQRS.
Also, if you ever created database views optimized for specific read use cases, that was a form of CQRS as well.
ElasticSearch or any other full-text search engine is also a kind of CQRS in action. It works by indexing data, usually from a relational database, and providing rich capabilities to query it. That’s exactly what CQRS is about.
CQRS & DDD
Some experts consider the Domain-Driven Design (DDD) to be an essential prerequisite for implementing the CQRS pattern.
Many of the ideas that informed the CQRS pattern arose from issues that DDD practitioners faced when applying the DDD approach to real-world problems.
If you decide to use the DDD approach, you may find that the CQRS pattern is a very natural fit for some of the bounded contexts that you identify within your system, and that it’s relatively straightforward to move from your domain model to the physical implementation of the CQRS pattern.
However, many people can point to projects where they have seen real benefits from implementing the CQRS pattern while not using the DDD approach for the domain analysis and model design.
In summary, the DDD approach is not a prerequisite for implementing the CQRS pattern, but in practice, they do often go together
Quick Summary
Command Query Responsibility Segregation is a pattern originating from the command-query separation principle. CQRS extends CQS to the architectural level. Just like CQS encourages you to split a method into two methods, a query, and a command, CQRS encourages you to untangle a single, unified domain model and create two models: one for handling commands, and the other one for handling queries.
CQRS allows us to make different decisions for reads and writes, which in turn brings three benefits: scalability, performance, and the biggest one, simplicity.
You can view CQRS as the single responsibility principle applied at the architectural level. In the end, you get two models, each of which does only one thing, and does it well.
We also discussed examples of applying the CQRS pattern in the real world. ElasticSearch and database views are among them.
In the next section, we will look at a sample project that’s implemented without the CQRS pattern in mind. We will analyze it, discuss its drawbacks, and then start making steps towards implementing CQRS.
Introducing a Sample Project
The source code for this sample project is available on GitHub. There would be different branches in the source code repository. You can follow our discussion throughout this article and refactor the application in the before branch.
You can see that the project folder contains three projects: API, Logic, and UI. The API is an ASP. NET Core application that targets. NET Core 3.0. Logic also targets. NET Core 3.0, and the UI is an Angular application.
Note: The UI project is made using the Angular project template provided in the ASP.NET Core application within Visual Studio. To run API and UI project simultaneously run the API project first and then right-click on the UI project and select Debug > Start new instance.
Now let us look into the code,
Let’s look at the domain model first in the Logic project. Our main domain class is Customer. It consists of FirstName, LastName, and Age. It also has a collection of Address. Each address has information like Street and City. Aside from constructors, there’s also an Update method that updates the Customer.
Customer.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
public class Customer : BaseEntity<long>
{
public string FirstName { get; private set; }
public string LastName { get; private set; }
public int Age { get; private set; }
public virtual ICollection<Address> Addresses { get; private set; }
private Customer() //For EF
{
}
public Customer(
string firstName,
string lastName,
int age,
ICollection<Address> addresses
)
{
FirstName = firstName;
LastName = lastName;
Age = age;
Addresses = addresses;
}
public void Update(
string firstName,
string lastName,
int age,
ICollection<Address> addresses
)
{
FirstName = firstName;
LastName = lastName;
Age = age;
Addresses.Clear();
foreach (var address in addresses)
{
Addresses.Add(address);
}
}
}
Address.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class Address : BaseEntity<long>
{
public string Street { get; private set; }
public string City { get; private set; }
public string ZipCode { get; private set; }
public bool IsPrimary { get; private set; }
public virtual Customer Customer { get; private set; }
private Address() //For EF
{
}
public Address(
string street,
string city,
string zipCode,
bool isPrimary
)
{
Street = street;
City = city;
ZipCode = zipCode;
IsPrimary = isPrimary;
}
}
Now,
Let’s see the CustomerController, which contains the actual application functionality. It has a unit of work, which is a wrapper on top of EntityFramework and transaction, and a repository name CustomerRepository. The GetAll method is what returns the customers to display in the table on the UI. It shows customers along with there primary address.
CustomerController.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
[Route("api/[controller]")]
[ApiController]
public class CustomersController : ControllerBase
{
private readonly UnitOfWork unitOfWork;
private readonly IMapper mapper;
private readonly CustomerRespository customerRepository;
public CustomersController(UnitOfWork unitOfWork,
IMapper mapper)
{
this.unitOfWork = unitOfWork;
this.mapper = mapper;
customerRepository = new CustomerRespository(unitOfWork);
}
// GET: api/Customers
[HttpGet]
public IActionResult Get()
{
var customers = customerRepository.GetAll();
var customersDto = mapper.Map<List<CustomerDto>>(customers);
return Ok(customersDto);
}
// GET: api/Customers/5
[HttpGet("{id}", Name = "Get")]
public async Task<IActionResult> Get(long id)
{
var customer = await customerRepository.GetByIdAsync(id);
if (customer == null) return NotFound();
var customerDto = mapper.Map<CustomerDto>(customer);
return Ok(customerDto);
}
// POST: api/Customers
[HttpPost]
public async Task<IActionResult> Post([FromBody] CustomerDto value)
{
var customer = new Customer(
value.FirstName,
value.LastName,
value.Age,
GetAddresses(value.Addresses)
);
customerRepository.Add(customer);
await unitOfWork.CommitAsync();
var customerDto = mapper.Map<CustomerDto>(customer);
return Created($"api/Customers/{customer.Id}", customerDto);
}
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> Put(long id, [FromBody] CustomerDto value)
{
var customer = await customerRepository.GetByIdAsync(id);
if (customer == null) return NotFound();
customer.Update(
value.FirstName,
value.LastName,
value.Age,
GetAddresses(value.Addresses)
);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
// DELETE: api/Customers/5
[HttpDelete("{id}")]
public async Task<IActionResult> Delete(int id)
{
var customer = await customerRepository.GetByIdAsync(id);
if (customer == null) return NotFound();
customerRepository.Delete(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
private ICollection<Address> GetAddresses(ICollection<AddressDto> addresses)
{
return addresses.Select(a =>
{
return new Address(
a.Street,
a.City,
a.ZipCode,
a.IsPrimary
);
}).ToList();
}
}
Let’s see the repository class as well:
CustomerRepository.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
public sealed class CustomerRespository
{
private readonly UnitOfWork _unitOfWork;
public CustomerRespository(UnitOfWork unitOfWork)
{
_unitOfWork = unitOfWork;
}
public Task<Customer> GetByIdAsync(long id)
{
return _unitOfWork.Query<Customer>()
.Include(nameof(Customer.Addresses))
.SingleOrDefaultAsync(c=>c.Id == id);
}
public void Add(Customer customer)
{
_unitOfWork.Add(customer);
}
public void Update(Customer customer)
{
_unitOfWork.Update(customer);
}
public void Delete(Customer customer)
{
_unitOfWork.Delete(customer);
}
public IReadOnlyCollection<Customer> GetAll()
{
return _unitOfWork.Query<Customer>()
.Include(nameof(Customer.Addresses))
.ToList();
}
}
Here’s the repository method that does the actual filtration. We first form an IQueryable that represents a SQL query for the database. We build up this query and include addresses by adding an Include clause to it. After that, we force EF to execute it and give us the resulting list of customers, and then in the second filter, we return the primary address. The later logic is written in the CustomerDto. Like this,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class CustomerDto
{
public long Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public virtual ICollection<AddressDto> Addresses { get; set; }
//Logic to return primary address or first address or empty dto
public AddressDto PrimaryAddress =>
Addresses.FirstOrDefault(a=>a.IsPrimary)
?? Addresses.FirstOrDefault()
?? new AddressDto();
}
Alright, so after the repository returns us all those domain objects, we convert them into DTOs, data transfer objects, and return to the client.
The code from CustomerController to return customer dtos:
1
2
3
4
5
6
7
8
9
10
11
// GET: api/Customers
[HttpGet]
public IActionResult Get()
{
var customers = customerRepository.GetAll();
//here we used automapper to convert models into dtos
var customersDto = mapper.Map<List<CustomerDto>>(customers);
return Ok(customersDto);
}
And Finally,
Here’s the Startup class.
Startup.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class Startup
{
...
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
services.AddDbContext<ApplicationDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("ApplicationDbContext")));
services.AddScoped<UnitOfWork>();
...
}
...
}
As UnitOfWork is a wrapper on top of DbContext themselves and should be instantiated and disposed of on each web request we used the AddScoped method to do exactly that.
Alright, that’s it for the application code base. Let’s now talk about its drawbacks.
Application Code Drawbacks
Let’s now discuss the drawbacks of the above code. You might not even realize that there is something wrong with this codebase.
So, what is it?
As we discussed in the first module, CQRS brings us three benefits:
- Scalability
- Performance
- Simplicity
Scalability is something we will talk about later in this article, and it’s not obvious that this application suffers from scalability issues anyway, so let’s skip it for now.
What about performance? Well, let’s open the CustomerRepository once again. This is the method that filters the customers and there primary address to show in the UI table. What can you tell about its performance?
Up to this moment, this method operates upon an IQueryable, which is good because all the LINQ statements made upon an IQueryable object translate into the corresponding SQL. It means that this Include statement is done in the database itself, which is exactly what we want.
But here, we force the ORM to fetch all the addresses with this customer into memory, and only after that, continue narrowing them down to find the primary address. It means that the database will send us an excessive amount of data, which we then filter manually in the memory.
The code we wrote in the repository to fetch all the addresses of a given customer:
1
2
3
return _unitOfWork.Query<Customer>()
.Include(nameof(Customer.Addresses)) //fetch all the addresses with this customer into memory
.ToList();
The code we wrote in customer dto to find primary address:
1
2
3
4
5
//find the primary address or first address or empty dto
public AddressDto PrimaryAddress =>
Addresses.FirstOrDefault(a=>a.IsPrimary)
?? Addresses.FirstOrDefault()
?? new AddressDto();
This is a suboptimal solution and can hit the performance quite badly in a complex application. It’s not noticeable in our sample application, of course, but that’s because there are just a few customers and addresses in our database. In a real-world project, with hundreds of thousands or even millions of records, it would.
Ideally, you should transfer only the minimum amount of data between the server and its database.
Another performance problem that comes up quite often is the problem called N+1. It’s when the ORM first fetches the customers, and then for each of them performs a separate call to retrieve their addresses, and then another one to get each of the corresponding children entity in any. So instead of just one database roundtrip, you end up with several of them, and the more customers there are, the more roundtrips you will have.
In most cases, you can overcome this problem by instructing the ORM to include the navigation properties, which we are already doing here, but it’s not always possible, and it’s very easy to overlook this issue when relying on the ORM to query the database.
Alright, and what about the code complexity? Is our code well-structured and easy to understand? Not really.
Look at the Update method once again. We are trying to do too many things here. We update the customer fields along with this we also delete all the addresses it has and then again add the new addresses. We can write code to figure out to update existing address and create new address but still, it will increase the code complexity.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class Customer : BaseEntity<long>
{
...
public void Update(
string firstName,
string lastName,
int age,
ICollection<Address> addresses
)
{
FirstName = firstName;
LastName = lastName;
Age = age;
Addresses.Clear();
foreach (var address in addresses)
{
Addresses.Add(address);
}
}
}
There is just too much going on here. This method violates the single responsibility principle, one of the SOLID principles from Bob Martin.
Another hint that tells us about the violation is this CustomerDto. It’s used for both sending the data to the client, and receiving it back when updating the customer. And because of that, some of the fields here remain unused in certain scenarios.
CustomerDto.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
public class CustomerDto
{
public long Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public virtual ICollection<AddressDto> Addresses { get; set; }
public AddressDto PrimaryAddress =>
Addresses.FirstOrDefault(a=>a.IsPrimary)
?? Addresses.FirstOrDefault()
?? new AddressDto();
}
For example, when updating the primary address, the user needs to only specify either an address that needs to be marked primary, but we are sending the whole customer dto along with their addresses to the server. This is a very CRUD approach, and it’s not the best way to organize the application code.
The code where we are updating customer and addresses together:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> Put(long id, [FromBody] CustomerDto value)
{
var customer = await customerRepository.GetByIdAsync(id);
if (customer == null) return NotFound();
customer.Update(
value.FirstName,
value.LastName,
value.Age,
GetAddresses(value.Addresses)
);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
private ICollection<Address> GetAddresses(ICollection<AddressDto> addresses)
{
return addresses.Select(a =>
{
return new Address(
a.Street,
a.City,
a.ZipCode,
a.IsPrimary
);
}).ToList();
}
What we are doing here is we essentially merge all the possible modifications to the customers into a single giant update method, whereas each of those modifications should have their own representation.
This artificial merge of responsibilities entails an increase of complexity, which in turn, damages the code base maintainability. This is especially painful in long-running projects where complexity tends to pile up over time and at some point becomes so immense that the whole application moves to the category of legacy applications.
It’s still valuable for the business, but no one dares to touch it as every modification is likely to introduce new defects. It’s important not to allow such a growth of complexity, and Domain-Driven Design in general, and CQRS in particular, are very good at it.
We will start untangling our codebase in the next section.
The codebase we saw now is a typical CRUD operation. This thinking in terms of create, read, update, and delete operations is called CRUD-based thinking.

Domain models
Our domain model is organized quite well and mostly encapsulated. If you look at the customer and address entity, they both have read-only properties and don’t have a setter.
1
2
3
4
5
6
7
8
9
public class Customer : BaseEntity<long>
{
public string FirstName { get; private set; }
public string LastName { get; private set; }
public int Age { get; private set; }
public virtual ICollection<Address> Addresses { get; private set; }
...
}
The parameter-less constructor is hidden. We expose a nice rich constructor instead that accepts required parameters, which explicitly tells the client code that these pieces of data are required to create a new customer or address.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class Customer : BaseEntity<long>
{
...
public void Update(
string firstName,
string lastName,
int age,
ICollection<Address> addresses
)
{
FirstName = firstName;
LastName = lastName;
Age = age;
Addresses.Clear();
foreach (var address in addresses)
{
Addresses.Add(address);
}
}
}
Other than that, the encapsulation here is pretty solid. Our domain model is not anemic. If you want to learn more about anemic domain models and how to transform them into rich and highly encapsulated ones, check out Shifting from Anemic Domain Model to Rich Domain Model.
Quick Summary
Till now we saw the initial version of the application we’ll be working on throughout this article.
The two major drawbacks with it are the use of the single model for both reads and writes, and the CRUD-based thinking.
The first issue leads to the inability to optimize database queries. You saw that we had to fetch an excessive amount of data from the database because the ORM doesn’t support the kind of querying we need. It’s also easy to fall into the N+1 problem where you end up with multiple roundtrips to the database instead of just one.
The second issue leads to an unnecessary increase in complexity. Because the application tries to fit all operations into the narrow box of create, read, update, and delete operations, what we end up with is the merging of all customer modifications into a single giant update method, which is a violation of the single responsibility principle; SRP for short.
In the next section, we will start refactoring away from the CRUD-based interface towards the task-based interface. You will see how it simplifies the code base and helps improve the user experience.
Refactoring Towards a Task-based Interface
Before learning a task-based interface we must first understand what is crud based interface.
CRUD-based Interface
As we discussed, all operations in an application, fundamentally fall into one of the four categories: create, read, update, and delete; CRUD for short. And it’s true.
However, it’s never a good idea to organize your application along these lines, except for the simplest cases.
Such an organization can have a devastating effect on your system, and not only in terms of its maintainability. It damages the user experience, too.
We will call this approach to code design CRUD-based interface, and the overarching mentality, CRUD-based thinking.
So, what’s the problem with it, exactly?
Problems with CRUD based thinking
Uncontrolled growth of complexity
As you saw in the previous example a single update method captures all the changes.
And the thing is a single method that captures all operations that somehow mutate an object, leads to the enormous expansion of that method. At some point the complexity becomes unbearable.
This, in turn, entails lots of bugs when modifying something in the code base and failures to meet project deadlines and quality standards. And this point comes much sooner than you might realize.
Even our quite simple application exhibits those traits. Imagine how it would look if we add a few more pieces of data with their own business rules to the customer class.
CRUD-based user experience
The CRUD-based thinking spills over from the code to the user interface, and the same issues that plague the code itself infect the user experience, too.
Look at our application for example. If I try to update the customer, does it make sense that, when I want to mark a primary address the UI shows me with all the possible modifications like user information? Not at all.
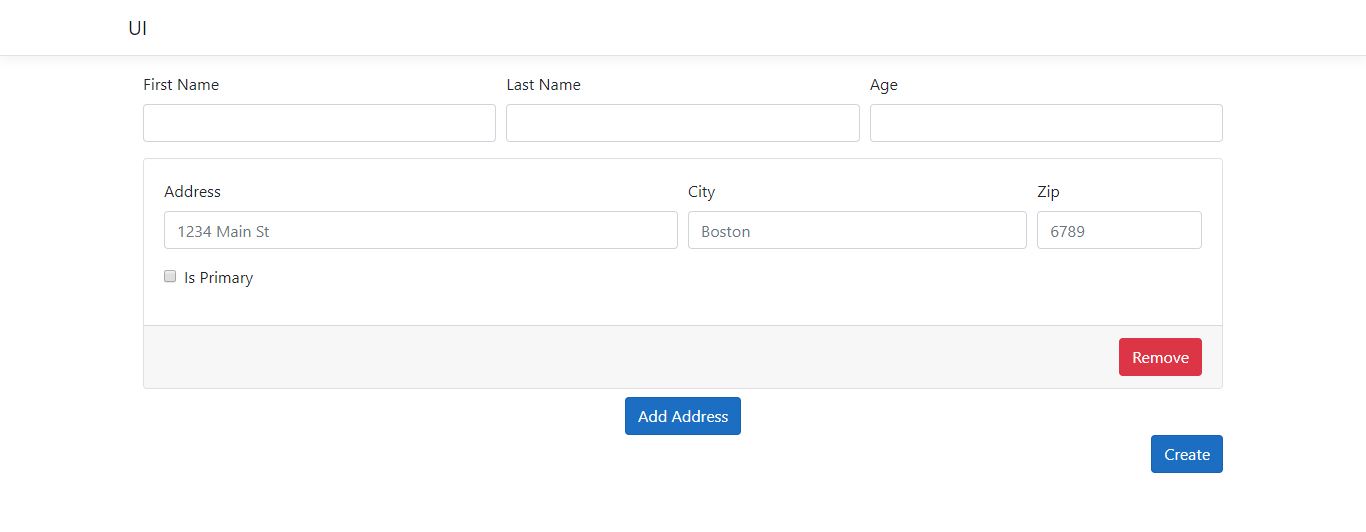
What’s happening here is because there are too many features lumped together on a single screen, the user has to figure them all out on their own.
Look at this screen once again. How many features are in here? At least four. Editing the customer’s personal information, inserting a new address, marking one of the addresses as primary, and removing an address, and it will take a while for a user to uncover them all.
The UI should guide the user through the process, not crash them with the full application functionality on a single giant window.
Overall, the focus on user experience should become an integral part of the development process, which rarely happens when CRUD-based thinking is in place.
As you can see, CRUD-based thinking affects both the codebase and the user experience. This is why I call the result CRUD-based interface; not user interface, but just interface.
So, how to fix this issue? Enters Task-based interface
Task-based Interface
The opposite of the CRUD-based interface is a task-based interface, and that’s what we need to replace our current design with. The task-based interface is the result of identifying each task the user can accomplish with an object in the application.
This is why its name is task-based, and assigning a separate window to each of them, and by extension, introducing a separate API endpoint, too.
This idea takes root in the concept of intuitive UI. Each window should implement a single distinctive operation. We need to restore the single responsibility principle, so to speak, and untangle our over-complicated update window and the giant update method.
The task-based interface makes it much easier for users to explore the software and learn what he or she can do with it.
Currently, the application’s business process is in the minds of people who developed it. Users must discover the correct process on their own.
After moving towards the single responsibility principle and the task-based interface, each window on the screen becomes self-describing and intuitive.
Sorting out the Update Method
Alright, here’s our update method again. Currently, it is object-centric, meaning that it tries to deal with the whole customer object.
Here’s our Update method:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> Put(long id, [FromBody] CustomerDto value)
{
var customer = await customerRepository.GetByIdAsync(id);
if (customer == null) return NotFound();
customer.Update(
value.FirstName,
value.LastName,
value.Age,
GetAddresses(value.Addresses)
);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
private ICollection<Address> GetAddresses(ICollection<AddressDto> addresses)
{
return addresses.Select(a =>
{
return new Address(
a.Street,
a.City,
a.ZipCode,
a.IsPrimary
);
}).ToList();
}
What we need to do instead is split it into several task-centric windows, each accomplishing its own separate task.
As we discussed before, there are four such tasks:
- Editing the customer’s personal information,
- Inserting customer’s address,
- Marking one of the customer’s addresses as primary,
- and removing the customer’s address.
So, let’s do that:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> EditCustomerInfo(long id, [FromBody] EditCustomerDto value)
{
var customer = await customerRepository.GetByIdAsync(id);
if (customer == null) return NotFound();
customer.Update(
value.FirstName,
value.LastName,
value.Age
);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
// POST: api/Customers/5/Addresses
[HttpPost("{customerId}/Addresses")]
public async Task<IActionResult> AddAddress(long customerId, [FromBody] CreateAddressDto value)
{
var customer = await customerRepository.GetByIdAsync(customerId);
if (customer == null) return NotFound();
var address = new Address(
value.Street,
value.City,
value.ZipCode
);
customer.AddAddress(address);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
var addressDto = mapper.Map<AddressDto>(address);
return Ok(addressDto);
}
// Put: api/Customers/5/Addresses/1/MarkPrimay
[HttpPut("{customerId}/Addresses/{addressId}/MarkPrimary")]
public async Task<IActionResult> MarkPrimary(long customerId, long addressId)
{
var customer = await customerRepository.GetByIdAsync(customerId);
if (customer == null) return NotFound();
var address = customer.Addresses.SingleOrDefault(a => a.Id == addressId);
if (address == null) return NotFound();
customer.MarkPrimay(address);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
// DELETE: api/Customers/5/Addresses/1
[HttpDelete("{customerId}/Addresses/{addressId}")]
public async Task<IActionResult> RemoveAddress(long customerId, long addressId)
{
var customer = await customerRepository.GetByIdAsync(customerId);
if (customer == null) return NotFound();
var address = customer.Addresses.SingleOrDefault(a => a.Id == addressId);
if (address == null) return NotFound();
customer.RemoveAddress(address);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return NoContent();
}
Here we untangled the customer update method. We have split it into four methods, each implementing its own distinctive task. - Editing the customer’s personal information, inserting the customer’s address, marking one of the customer’s addresses as primary, and removing the customer’s address.
In other words, we refactored the update API endpoint, which had a CRUD-based interface into several smaller ones, which are now task-based. Each of those methods adheres to the single responsibility principle, meaning that they are responsible for doing one task and one task only.
Note that along with the API endpoint, we modified the DTOs we are using, too. Before the refactoring, the Update method relied on this large and clunky CustomerDto in which we lumped together fields to accommodate all possible modifications that could be done to the customer. And not only that, we used this same DTO for displaying customers’ info in the table.
Clunky CustomerDto:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class CustomerDto
{
public long Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
public virtual ICollection<AddressDto> Addresses { get; set; }
public AddressDto PrimaryAddress =>
Addresses.FirstOrDefault(a=>a.IsPrimary)
?? Addresses.FirstOrDefault()
?? new AddressDto();
}
public class AddressDto
{
public long Id { get; set; }
public string Street { get; set; }
public string City { get; set; }
public string ZipCode { get; set; }
public bool IsPrimary { get; set; }
}
New task-based interface DTOs:
1
2
3
4
5
6
public class EditCustomerDto
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
}
1
2
3
4
5
6
public class CreateAddressDto
{
public string Street { get; set; }
public string City { get; set; }
public string ZipCode { get; set; }
}
This new task-based interface now has a separate DTO for each of the tasks. All of them are small and concise and have only the info required to accomplish the task at hand.
Alright, so we were able to simplify our code after refactoring towards the task-based API. Let’s now see how this change affects the user interface.
Task-based User Interface
I won’t bother you showing how I’m refactoring the UI. After all, this article is not about user interfaces, but it’s still interesting to look at the result, so here it is.
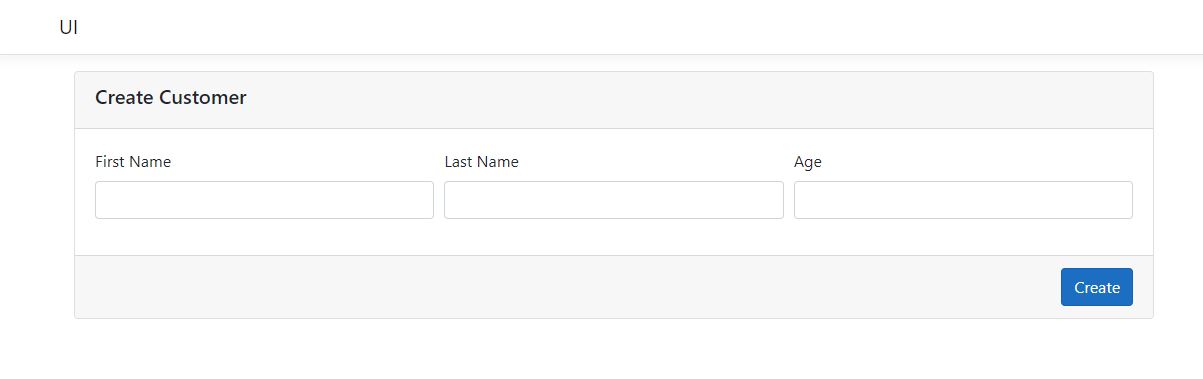
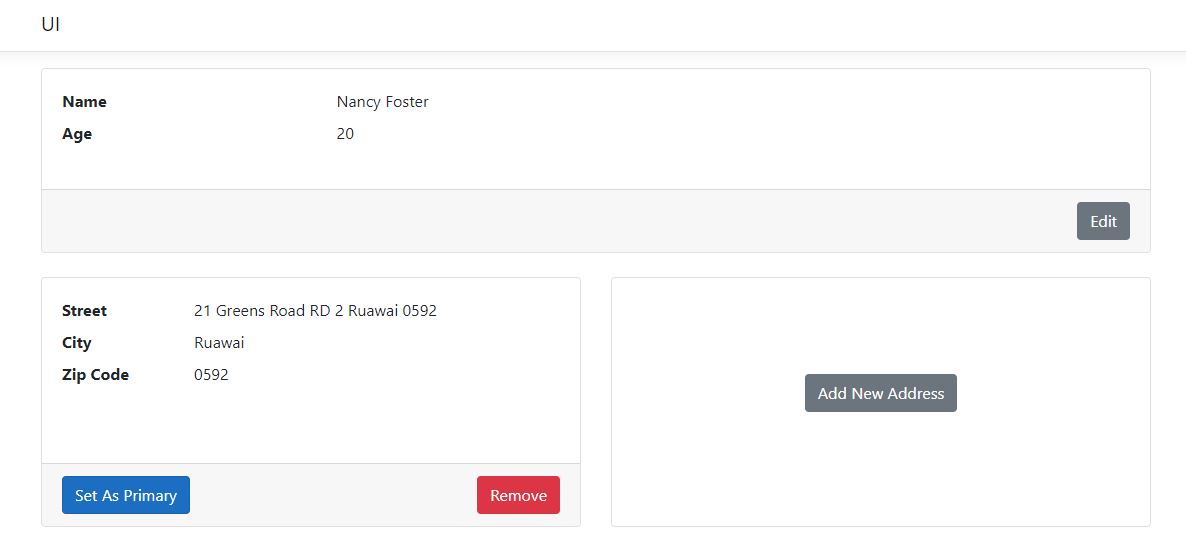
This natural flow of events makes for great user experience. Every single operation is intuitive and asks for the minimum amount of information to accomplish the task at hand.
Now compare it to the old version with the CRUD-based UI. All four operations are lumped together on a single big screen.
Dealing with Create and Delete Methods
Alright, we’ve dealt with the Update method. We extracted it into four smaller, task-based ones, but what about create and delete API endpoints? At first glance, they seem fine.
However, the create method has the same problem. Create endpoint still uses CustomersDto to accept data from the outside. It is the same DTO the UI uses to display the customers in the grid, and it has fields we don’t need when creating a customer, for example, addresses. So, we need to come up with a separate DTO that would contain only the fields required for this task.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// POST: api/Customers
[HttpPost]
public async Task<IActionResult> CreateCustomer([FromBody] CreateCustomerDto value)
{
var customer = new Customer(
value.FirstName,
value.LastName,
value.Age
);
customerRepository.Add(customer);
await unitOfWork.CommitAsync();
var customerDto = mapper.Map<CustomerDto>(customer);
return Created($"api/Customers/{customer.Id}", customerDto);
}
1
2
3
4
5
6
public class CreateCustomerDto
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
}
And here’s how the final UI looks now.
Our interface, both API and UI, is now completely task-based.
Note, however, that task-based interface is not a prerequisite for CQRS per se. You can have one with or without the other, but the problem of CRUD-based thinking often goes hand in hand with CQRS. People who suffer from having a single model that handles both reads and writes usually also suffer from CRUD-based thinking.
Also note that sometimes, the CRUD-based interface is just fine. If your application is not too complex, or you are not going to maintain or evolve it in the future, no need to invest in the task-based interface.
Quick Summary
So far, you saw how we refactored our application towards the task-based interface. You learned what CRUD-based interface and CRUD-based thinking are.
CRUD-based thinking is when people try to fit all operations with an object into a narrow box of create, read, update, and delete operations. The CRUD-based interface is the result of CRUD-based thinking.
The Task-based interface is the opposite of the CRUD-based interface. It is the result of identifying each task the user can accomplish with an object and assigning a separate window to each of them. This also affects both the UI and the API.
In terms of the UI, the single object-centric window gets split into several task-centric ones. In terms of the API, you introduce several API endpoints dedicated to accomplishing one single task. As a result, both UI and API becomes much simpler to understand and maintain.
In the next section, we will segregate commands from queries in our application, an essential part of the CQRS pattern.
Segregating Commands and Queries
We refactored our application towards the task-based interface. All the operations are now clearly defined and have their own API endpoints.
Our next goal would be to introduce explicit commands and queries for each of those API endpoints.
This will help us by bringing in the benefits of CQRS: scalability, performance, and simplicity.
Alright, so here it is, our CustomerController outlining.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
public class CustomersController : ControllerBase
{
...
// GET: api/Customers
[HttpGet]
public IActionResult GetList()
{
...
}
// GET: api/Customers/5
[HttpGet("{id}", Name = "Get")]
public async Task<IActionResult> GetCustomer(long id)
{
...
}
// POST: api/Customers
[HttpPost]
public async Task<IActionResult> CreateCustomer([FromBody] CreateCustomerDto value)
{
...
}
// POST: api/Customers/5/Addresses
[HttpPost("{customerId}/Addresses")]
public async Task<IActionResult> AddAddress(long customerId, [FromBody] CreateAddressDto value)
{
...
}
// Put: api/Customers/5/Addresses/1/MarkPrimay
[HttpPut("{customerId}/Addresses/{addressId}/MarkPrimary")]
public async Task<IActionResult> MarkPrimary(long customerId, long addressId)
{
...
}
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> EditCustomerInfo(long id, [FromBody] EditCustomerDto value)
{
...
}
// DELETE: api/Customers/5
[HttpDelete("{id}")]
public async Task<IActionResult> DeleteCustomer(int id)
{
...
}
// DELETE: api/Customers/5/Addresses/1
[HttpDelete("{customerId}/Addresses/{addressId}")]
public async Task<IActionResult> RemoveAddress(long customerId, long addressId)
{
...
}
}
As we discussed in the previous module, any operation can be either a command or a query:
-
A query doesn’t mutate the external state, such as that of the database, but returns something to the caller.
-
A command is the opposite of that. It does mutate the external state but doesn’t return anything to the client.
Let’s first outline which of the API endpoints here represent commands and which queries.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
public class CustomersController : ControllerBase
{
...
// GET: api/Customers
[HttpGet]
public IActionResult GetList() //Query
{
...
}
// GET: api/Customers/5
[HttpGet("{id}", Name = "Get")]
public async Task<IActionResult> GetCustomer(long id) //Query
{
...
}
// POST: api/Customers
[HttpPost]
public async Task<IActionResult> CreateCustomer([FromBody] CreateCustomerDto value) //Command
{
...
}
// POST: api/Customers/5/Addresses
[HttpPost("{customerId}/Addresses")]
public async Task<IActionResult> AddAddress(long customerId, [FromBody] CreateAddressDto value) //Command
{
...
}
// Put: api/Customers/5/Addresses/1/MarkPrimay
[HttpPut("{customerId}/Addresses/{addressId}/MarkPrimary")]
public async Task<IActionResult> MarkPrimary(long customerId, long addressId) //Command
{
...
}
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> EditCustomerInfo(long id, [FromBody] EditCustomerDto value) //Command
{
...
}
// DELETE: api/Customers/5
[HttpDelete("{id}")]
public async Task<IActionResult> DeleteCustomer(int id) //Command
{
...
}
// DELETE: api/Customers/5/Addresses/1
[HttpDelete("{customerId}/Addresses/{addressId}")]
public async Task<IActionResult> RemoveAddress(long customerId, long addressId) //Command
{
...
}
}
Now, we need to introduce separate classes for each command and query in our application, and so we will do exactly that. We’ll start with the EditCustomerInfo method.
Let’s create a new class EditCustomerInfoCommand. Make it public and sealed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public sealed class EditCustomerInfoCommand
{
public EditCustomerInfoCommand(long id, string firstName, string lastName, int age)
{
Id = id;
FirstName = firstName;
LastName = lastName;
Age = age;
}
public long Id { get; }
public string FirstName { get; }
public string LastName { get; }
public int Age { get; }
}
Now, what we could do with this command is we could first instantiate it in the controller method, and then somehow execute, for example, by calling an Execute method on the command itself.
1
2
3
4
5
6
var command = new EditCustomerInfoCommand(id,
value.FirstName,
value.LastName,
value.Age);
command.Execute();
That would be the first choice for most of us, programmers, who want to make sure that the command is properly encapsulated.
However, this is not the best design decision, because we would conflate two different concerns here. Command itself should represent what needs to be done. It should be a declaration of intent, so to speak. The execution is a different matter.
The execution often refers to the outside world, such as the database and third-party systems, and you don’t want to delegate this responsibility directly to the commands.
So, because we don’t want the command to execute itself, there should be a separate class that does that.
And here it is, EditPersonalInfoCommand handler. It will contain a single method, Handle, that accepts the command.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public sealed class EditCustomerInfoCommandHandler
{
private readonly DbContextFactory dbContextFactory;
public EditCustomerInfoCommandHandler(DbContextFactory dbContextFactory)
{
this.dbContextFactory = dbContextFactory;
}
public async Task<Validation<Unit>> Handle(EditCustomerInfoCommand command)
{
var unitOfWork = new UnitOfWork(dbContextFactory);
var customerRepository = new CustomerRepository(unitOfWork);
var customer = await customerRepository.GetByIdAsync(command.Id);
if (customer == null) return Error("Customer not found!");
customer.Update(
command.FirstName,
command.LastName,
command.Age
);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
return Unit();
}
}
Now the problem with this approach is that each handler class will have its own public API. There would be no common interface between them, and so we won’t be able to extend them with new functionality.
As we will introduce decorators on top of the command handlers so that we could enrich those handlers and introduce cross-cutting concerns to our application. And so we need a common interface between all our commands and command handlers.
For that, we need to introduce a couple of new types. The first one is the ICommand. It’s a marker interface, which means that its sole purpose is to mark the commands in our code base, like this.
1
2
3
public interface ICommand<TOutput>
{
}
The second one is ICommandHandler.
1
2
3
4
public interface ICommandHandler<TCommand, TOutput> where TCommand : ICommand<TOutput>
{
TOutput Handle(TCommand command);
}
It’s the interface that works with a particular type of commands, and this type is specified here with the TCommand type parameter. We can put a restriction here that would require TCommand to be of a type that implements the ICommand interface.
Also, along with the type of the TCommand itself, we declared the TOutput type of the result which the handler then will return to the caller.
This way, all our command handlers will have a common interface, which would make it easy to decorate them later. Alright, so having this groundwork laid out. Our final command and handler will look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public sealed class EditCustomerInfoCommand : ICommand<Task<Validation<Unit>>>
{
...
}
public sealed class EditCustomerInfoCommandHandler : ICommandHandler<EditCustomerInfoCommand, Task<Validation<Unit>>>
{
...
public async Task<Validation<Unit>> Handle(EditCustomerInfoCommand command)
{
...
}
}
Now, if you look at the return type it is a bit different, we could make our command handler return an instance of IActionResult, too, but that’s not the best design decision. It’s better to leave the ASP. NET concerns to the controller, and keep the command handler free of such concerns.
But how can we return an error from the command handler then? That’s a good question. One way could be to throw an exception, which is also not the best way to deal with this issue.
Exceptions used for controlling the program flow and specifically for validation, tend to complicate the code base, and it’s better to use an explicit return value instead.
A classic functional approach to this problem is to use the Either type, which, in the context of an operation with two possible outcomes, captures details about the outcome that has taken place. For more information, see Functional error handling.
LaYumba.Functional is a utility library for programming functionally in C# includes the following two variations for representing outcomes:
Validation
Validation<T> — You can think of this as an Either that has been particularized to IEnumerable<Error>:
1
Validation<T> = Invalid(IEnumerable<Error>) | Valid(T)
Validation is just like an Either where the failure case is fixed to IEnumerable <Error>, making it possible to capture multiple validation errors.
Exceptional
Exceptional<T> —Here, failure is fixed to System.Exception:
1
Exceptional<T> = Exception | Success(T)
Exceptional can be used as a bridge between an exception-based API and functional error handling.
As you can see we used the Validation<T> as our return type and Unit as a type argument to represent the absence of data. Unit is a typical functional way to represent a void operation.
1
public sealed class EditCustomerInfoCommand : ICommand<Task<Validation<Unit>>>
That was easy! Now, Validation type contains the Match method to compute a different value depending on the state of an either:
Now that the Handle method returns a Validation instance, here, we can call result.Match to compute our final outcome in the controller.
1
2
3
4
5
6
7
var result = await handler.Handle(command);
return result.Match<IActionResult>(
(errors) => BadRequest(errors),
(valid) => NoContent()
);
If the result is successful, call NoContent, and if not, call BadRequest with the error from the result instance.
Now, the problem with the whole command and handler design is that we need to instantiate the handlers manually in each controller method, like this:
1
var handler = new EditCustomerInfoCommandHandler(dbContextFactory);
which would be quite repetitive, or we would have to inject them into the controller’s constructor, like this:
1
2
3
4
5
6
7
8
9
10
public class CustomersController : ControllerBase
{
...
public CustomersController(EditCustomerInfoCommandHandler handler, IMapper mapper)
{
this.handler = handler;
this.mapper = mapper;
}
}
As you can see, there are quite a few of controller methods here, and we would need a handler for each of them, and so you can imagine that the number of parameters in the constructor will get out of control very quickly.
You don’t want to find yourself in this situation either, because that would damage the maintainability of the codebase.
So what we can do instead? We can leverage the ASP. NET Core dependency injection infrastructure.
Leveraging ASP.NET Core Dependency Injection to Resolve Handlers
As we know, it’s not very convenient to create handlers in every controller action manually. What we can do instead is we can leverage the ASP. NET Core dependency injection mechanism to resolve the command handlers for us.
For that, let’s create a helper class. I’ll name it Messages, make it public and sealed.
This class will be responsible for dispatching all our messages, all our commands, and queries.
1
2
3
4
5
6
7
8
9
10
11
public sealed class Messages
{
private readonly IServiceProvider serviceProvider;
public Messages(IServiceProvider serviceProvider)
{
this.serviceProvider = serviceProvider;
}
}
As you can see the constructor of this class accepts an instance of the IServiceProvider interface, and save it to a private field. This interface is from ASP. NET Core; it’s part of the ASP. NET component model.
It implements the service locator pattern and gets, from the dependency injection container, a service of a given type. These are the types that you define in the startup class. Here it is.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Startup
{
...
public void ConfigureServices(IServiceCollection services)
{
services.AddSingleton<DbContextFactory>();
services.AddSingleton<Messages>();
services.AddTransient<ICommandHandler<EditCustomerInfoCommand, Task<Validation<Unit>>>,
EditCustomerInfoCommandHandler>();
...
}
}
So here, I’m adding the Messages class as a singleton, because there should be only one such class in our application.
And I’m also adding our command handler. This line will tell ASP. NET how to resolve the ICommandHandler interface of the type parameter, EditCustomerInfoCommand command and Task<Validation<Unit>> result.
Note: Here Unit is a data type that represents a void in the LaYumba package. It represents the absence of data.
Okay, let’s go back to the Messages class. It will dispatch commands using this, public void Dispatch method.
Here, we need to find a handler for the given command instance.
how to do that? We have the provider, which already knows how to resolve a handler for a particular ICommandHandler interface. We told it how to do that in the application Startup.
Now, we need to compose that interface and feed it into the provider, and we’ll do exactly that, like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public sealed class Messages
{
...
public TResult Dispatch<TResult>(ICommand<TResult> command)
{
var type = typeof(ICommandHandler<,>);
var argTypes = new Type[] { command.GetType(), typeof(TResult) };
var handlerType = type.MakeGenericType(argTypes);
dynamic handler = serviceProvider.GetService(handlerType);
TResult result = handler.Handle((dynamic)command);
return result;
}
}
Now our final code will look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class CustomersController : ControllerBase
{
private readonly Messages messages;
private readonly IMapper mapper;
public CustomersController(Messages messages, IMapper mapper)
{
this.messages = messages;
this.mapper = mapper;
}
...
// PUT: api/Customers/5
[HttpPut("{id}")]
public async Task<IActionResult> EditCustomerInfo(long id, [FromBody] EditCustomerDto value)
{
var command = new EditCustomerInfoCommand(id,
value.FirstName,
value.LastName,
value.Age);
var result = await messages.Dispatch(command);
return result.Match<IActionResult>(
(errors) => BadRequest(errors),
(valid) => NoContent()
);
}
...
}
Alright, so having this groundwork laid out, let’s discuss more about Command and Queries a bit.
Commands and Queries in CQRS
Now that we have our first command, let’s discuss commands and queries in more detail.
All messages in an application can be divided into three categories: commands, queries, and events.
- A command is a message that tells our application to do something,
- A query is a message that asks our application about something,
- An event is an informational message. Our application can generate an event to inform external applications about some changes.
Here’s how all three can be depicted together on a single diagram.
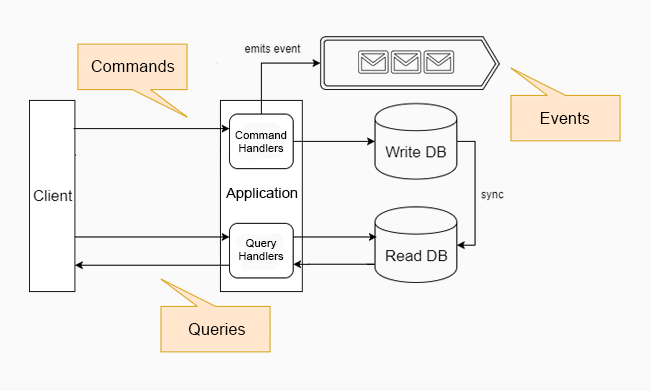
As you can see, the client sends commands and queries to our application to either tell it to do something or ask about something.
On the other end, our application communicates with external applications via events. It informs them about changes within the app.
We will not be focusing on events much in this article. Just keep in mind that it’s the same concept as domain events in DDD.
Naming Guidelines for Commands, Queries, and Events.
There are naming guidelines associated with all these three types of messages.
First of all, commands should always be in the imperative tense. That’s because they are telling the application to do something. EditCustomerInfoCommand is a good example here. It tells our application to edit, to modify the personal information of the Customer.
Queries usually start with the word Get, for example, GetList. That’s because queries ask the application to provide some data, and it’s hard to come up with something else other than the word Get for such a request.
Finally, events should always be in the past tense. That’s because they state a fact that already happened; some event that is significant for your domain model.
For example, we could raise a domain event, something like CustomerInfoChangedEvent, and the marketing department could subscribe to that event and update their records accordingly.
Note the difference in the semantics here, EditCustomerInfo versus CustomerInfoChanged. This distinction is very important.
By naming the command Edit Customer Information, you imply that the server can reject this message. It can reject executing it, for example, because the email in that command is invalid. On the other hand, the application cannot reject an event.
If your application receives an event named CustomerInfoChanged, there is nothing it can do about it. The operation it informs you about has already happened, and this event is just a notification about that fact.
Introducing a Query
As you can see, it’s quite useful to leverage the built-in ASP. NET dependency injection container. It does exactly what we need with very little effort on our part. Let’s now introduce a query.
Just like the ICommand interface, we need to create an IQuery one,
1
2
3
public interface IQuery<TResult>
{
}
and another interface for query handlers, where TQuery should implement the IQuery interface. It will also have a single method handle.
1
2
3
4
public interface IQueryHandler<TQuery, TResult> where TQuery : IQuery<TResult>
{
TResult Handle(TQuery query);
}
Alright, after all this preparation is done, we can finally proceed with the query itself. The query is going to be GetAllCustomerQuery.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public sealed class GetAllCustomerQuery : IQuery<Task<Validation<IReadOnlyCollection<Customer>>>>
{
public GetAllCustomerQuery()
{
}
public sealed class GetAllCustomerQueryHandler : IQueryHandler<GetAllCustomerQuery, Task<Validation<IReadOnlyCollection<Customer>>>>
{
private readonly DbContextFactory dbContextFactory;
public GetAllCustomerQueryHandler(DbContextFactory dbContextFactory)
{
this.dbContextFactory = dbContextFactory;
}
public async Task<Validation<IReadOnlyCollection<Customer>>> Handle(GetAllCustomerQuery query)
{
var unitOfWork = new UnitOfWork(dbContextFactory);
var customerRepository = new CustomerRepository(unitOfWork);
var customers = await customerRepository.GetAll();
return Valid(customers);
}
}
}
We’ve implemented one command and one query so far. Similarly, you can move all the remaining code from the controller to commands. I’ll leave it to you as an exercise.
Quick Summary
All messages in an application can be divided into three categories: commands, queries, and events.
A command is a message that tells the application to do something, a query is a message that asks the application about something, and an event is an informational message. It tells external applications about some changes significant to your domain. It’s important to properly name all three types of messages.
After refactoring the code of the customer controller it uses explicit command and query objects to do its work, and because of that, the controller itself has become a thin wrapper on top of these commands and queries.
In theory, you could even remove this controller. There’s not much value in it anyway. Here you can see all it does is it creates commands and dispatches them. In practice, however, there’s just too much of internal ASP. NET wiring that is tied to the presence of controllers.
Now,
We will discuss how to implement decorators upon the command and query handlers. It can be a very powerful mechanism that allows you to achieve great flexibility with little effort and maintenance cost.
Implementing Decorators upon Command and Query Handlers
In the previous section, we introduced explicit commands and queries in our code base and handlers for them. In this section, We will see how the changes we made so far, allows us to easily introduce cross-cutting concerns in our application.
Database Retries
Let’s say that we’ve got a new requirement. Our database goes offline from time to time, because the connection between the application and the database is unstable, and so we need to implement a retry mechanism to deal with this issue.
One way to implement this requirement in any particular handler would be to write something like this:
CreateCustomerCommandHandler.cs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public sealed class EditCustomerInfoCommandHandler : ICommandHandler<EditCustomerInfoCommand, Task<Validation<Unit>>>
{
...
public async Task<Validation<Unit>> Handle(EditCustomerInfoCommand command)
{
...
for (int i = 0; ; i++)
{
try
{
await unitOfWork.CommitAsync();
}
catch (Exception ex)
{
if (i >= 3 || !IsDatabaseException(ex))
throw;
}
}
return Unit();
}
}
Here, we wrap the Commit method call into a try-catch statement. This commit method is where the database transaction gets committed and all the SQL queries are executed.
So if there is any connection interruption between the application and the database server, it will show up in this line. This approach sounds feasible at first, but unfortunately, it wouldn’t work.
The issue here is that this Commit method is not the only one that reaches out to the database. We also have a line that retrieves the customer.
1
2
var customer = await customerRepository.GetByIdAsync(command.Id);
if (customer == null) return Error("Customer not found!");
If for some reason, the customer is no longer in the database between the first and the second attempt, you need to somehow show this fact and not just blindly keep retrying the operation.
And so it turns out that the only reliable way to implement the retry is to re-run the command handler as a whole, like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public async Task<Validation<Unit>> Handle(EditCustomerInfoCommand command)
{
for (int i = 0; ; i++)
{
try
{
var unitOfWork = new UnitOfWork(dbContextFactory);
var customerRepository = new CustomerRepository(unitOfWork);
var customer = await customerRepository.GetByIdAsync(command.Id);
if (customer == null) return Error("Customer not found!");
customer.Update(
command.FirstName,
command.LastName,
command.Age
);
customerRepository.Update(customer);
await unitOfWork.CommitAsync();
}
catch (Exception ex)
{
if (i >= 3 || !IsDatabaseException(ex))
throw;
}
}
return Unit();
}
Re-run the full code of the handle method, which as you can see, is quite verbose, and in addition to that, it means a lot of code duplication.
If we want to implement such a retry in any other command handler, we won’t have any choice other than copying and pasting this loop with the try/catch statement in all of our handlers.
Fortunately, there is a better way. As I mentioned in the previous section, we can take advantage of the unified interface all our command and query handlers implement and introduce decorators on top of them.
Database Retry Decorator
Alright, so let’s start with our first decorator.
1
2
3
4
5
6
7
8
9
10
public sealed class DatabaseRetryDecorator<TCommand, TOutput> : ICommandHandler<TCommand, TOutput>
where TCommand : ICommand<TOutput>
{
...
public TOutput Handle(TCommand command)
{
...
}
}
Inside the handle method, we will introduce a for loop that will retry the action three times, and inside of it, there will be a try-catch statement, like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public TOutput Handle(TCommand command)
{
for (int i = 0; ; i++)
{
try
{
//This line is where we will do the retry itself.
}
catch (Exception ex)
{
if (i >= 3 || !IsDatabaseException(ex))
throw;
}
}
}
So, how to do the actual retry? We need a reference to the handler this decorator decorates, and how to get it? We can request it to be injected into the constructor, like this:
1
2
3
4
5
6
7
8
private readonly ICommandHandler<TCommand, TOutput> _handler;
private readonly Config _config;
public DatabaseRetryDecorator(ICommandHandler<TCommand, TOutput> handler, Config config)
{
_config = config;
_handler = handler;
}
Now we can use this handler here, in the try-catch statement, handler. Handle, and return the result to the caller.
1
2
3
4
5
6
7
8
9
10
try
{
TOutput result = _handler.Handle(command);
return result;
}
catch (Exception ex)
{
if (i >= 3 || !IsDatabaseException(ex))
throw;
}
So the idea here is to catch any exception that pops up from the handler and then, if it’s related to the database connectivity issue, retry the same handle method once again, and we need to do that only if the number of attempts doesn’t exceed three.
The check as to whether the exception is a database connectivity exception will look like this. It should always have an inner exception with one of these two strings.
1
2
3
4
5
6
7
8
9
10
private bool IsDatabaseException(Exception exception)
{
string message = exception.InnerException?.Message;
if (message == null)
return false;
return message.Contains("The connection is broken and recovery is not possible")
|| message.Contains("error occurred while establishing a connection");
}
Our final decorator will look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public sealed class DatabaseRetryDecorator<TCommand, TOutput> : ICommandHandler<TCommand, TOutput>
where TCommand : ICommand<TOutput>
{
public DatabaseRetryDecorator(ICommandHandler<TCommand, TOutput> handler)
{
_handler = handler;
}
public TOutput Handle(TCommand command)
{
for (int i = 0; ; i++)
{
try
{
TOutput result = _handler.Handle(command);
return result;
}
catch (Exception ex)
{
if (i >= 3 || !IsDatabaseException(ex))
throw;
}
}
}
private bool IsDatabaseException(Exception exception)
{
string message = exception.InnerException?.Message;
if (message == null)
return false;
return message.Contains("The connection is broken and recovery is not possible")
|| message.Contains("error occurred while establishing a connection");
}
}
Alright, so now we need to register this decorator in the startup class like this:
1
2
3
4
5
6
7
8
services.AddTransient<ICommandHandler<EditCustomerInfoCommand, Task<Validation<Unit>>>>(
provider =>
{
return new DatabaseRetryDecorator<EditCustomerInfoCommand, Task<Validation<Unit>>>
(
new EditCustomerInfoCommandHandler(provider.GetService<DbContextFactory>())
)
});
Here it is, a delegate that returns an instance of the ICommandHandler. This factory itself accepts an instance of the IServiceProvider interface, the same interface we are using in the Messages class to resolve our handlers.
So, the delegate will look like this. It will instantiate the decorator, and also instantiate the handler and pass it as a parameter to the decorator’s constructor.
So, we have implemented our first decorator, which detects database connectivity failures and re-runs the same command handler several times, until it either reaches the limit of three attempts or gets a successful result, meaning a result without an exception.
Now that you saw the decorator pattern in action, it’s time to discuss it in more detail. So, what is it?
Decorator Pattern
Decorator is a class or a method that modifies the behavior of an existing class or method without changing its public interface, and thus, without affecting the clients of that class or method.
In our sample application, the decorator implemented the same ICommandHandler interface all other commands implement, but instead of being one of the true commands, it enhanced their behavior with additional logic.
And by doing so, it didn’t require us to modify any of the clients of this command handler.
Because we moved the retry logic into a separate class, we can keep the handlers themselves simple and focused on the actual business use cases, not the technical details such as database connectivity issues. We can separate these two concerns.
Moreover, as you introduce more and more decorators, their composition becomes increasingly rich in terms of functionality, and still, each separate element of this composition remains very simple.
Logging Decorator
Let’s say that we received another requirement, implement audit logging for our EditPersonalInfo command handler.
The stakeholders want to have a track in our audit log of the changes people make to their personal information, and that’s on top of the retry behavior we have at the moment.
We know how to deal with this request, by adding a new decorator. So, let’s do that.
I’m adding a new class to our decorator’s folder called AuditLoggingDecorator.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public sealed class AuditLoggingDecorator<TCommand, TOutput> : ICommandHandler<TCommand, TOutput>
where TCommand : ICommand<TOutput>
{
private readonly ICommandHandler<TCommand, TOutput> _handler;
public AuditLoggingDecorator(ICommandHandler<TCommand, TOutput> handler)
{
_handler = handler;
}
public TOutput Handle(TCommand command)
{
...
}
}
Just as our first decorator, it will implement the ICommandHandler interface. Implementing missing members, and injecting a handler in the constructor.
Now, in the Handle method, we want to somehow log the incoming command to have the audit trail.
1
2
3
4
5
6
7
8
9
public TOutput Handle(TCommand command)
{
string commandJson = JsonConvert.SerializeObject(command);
// Use proper logging here
Console.WriteLine($"Command of type {command.GetType().Name}: {commandJson}");
return _handler.Handle(command);
}
One way to do so would be to serialize it into a JSON and then log the resulting text.
In a real-world application, you need to inject a logger into the decorator the same way we did with the config instance in the previous decorator and use that logger instead of Console.WriteLine.
To use this new decorator, we need to adjust the Startup class, add it to the existing method factory, and pass the decorator we already have as a parameter.
1
2
3
4
5
6
7
8
services.AddTransient<ICommandHandler<EditCustomerInfoCommand, Task<Validation<Unit>>>>(provider =>
{
return new AuditLoggingDecorator<EditCustomerInfoCommand, Task<Validation<Unit>>>(
new DatabaseRetryDecorator<EditCustomerInfoCommand, Task<Validation<Unit>>>(
new EditCustomerInfoCommandHandler(provider.GetService<DbContextFactory>())
)
);
});
Note that the order in which you wrap one decorator on top of the others does matter.
Should we choose to inject these two instances the other way around, AuditLoggingDecorator inside the DatabaseRetryDecorator, we would be an audit record on every retry, which is not what we want here.
So, we have implemented our second decorator as well.
Streamlining the Decorator Configuration
As you can see, the decorator pattern along with the command and query handlers is a powerful mechanism that allows us to create complex behaviors using simple building blocks.
However, there’s one drawback to this implementation.
As you can see here, in the Startup class, we now have quite a convoluted configuration code, and that’s with just two decorators that we are using on just one command handler. As we continue to develop our application, this code will become too verbose very quickly.
We could extract it into a separate method, of course, but there is a better way. What we can do instead is we can define the decorators with attributes on the handler classes themselves, like this:
1
2
3
4
5
6
[AuditLog]
[DatabaseRetry]
public sealed class EditCustomerInfoCommandHandler : ICommandHandler<EditCustomerInfoCommand, Task<Validation<Unit>>>
{
...
}
This will allow us to apply a declarative approach where we could annotate the handlers we would like to enrich with additional functionality, using just a single line of code. And at the same time, this will allow us to get rid of all this configuration code.
So, how can we do that? Let’s see. First of all, we need to add the attributes I used in the EditPersonalInfo command handler. Here is the DatabaseRetryAttribute.
1
2
3
4
5
6
7
[AttributeUsage(AttributeTargets.Class, Inherited = false, AllowMultiple = true)]
public sealed class DatabaseRetryAttribute : Attribute
{
public DatabaseRetryAttribute()
{
}
}
It’s a standard attribute with nothing particularly interesting about it. The only thing to note is that its usage is restricted to classes. So, we can only put it on top of classes, but not methods, and here is the other one, AuditLogAttribute.
1
2
3
4
5
6
7
[AttributeUsage(AttributeTargets.Class, Inherited = false, AllowMultiple = true)]
public sealed class AuditLogAttribute : Attribute
{
public AuditLogAttribute()
{
}
}
Now it is time to map these attributes to the decorators, or more specifically, properly register our handlers, taking into account the decoration attributes. For that, I will create a new class, HandlerRegistration, make it static.
1
2
3
4
public static class HandlerRegistration
{
}
The only method this class will contain is the AddHandlers method, which would be an extension method on top of IServiceCollection.
1
2
3
4
public static void AddHandlers(this IServiceCollection services)
{
...
}
We could make it a regular static method instead, but it’s a nice convention to always define methods that register ASP. NET services as extension methods. Here’s what its usage will look like in the Startup class;
1
2
3
4
5
6
7
8
9
10
11
public class Startup
{
...
public void ConfigureServices(IServiceCollection services)
{
...
services.AddHandlers();
}
}
just a single method instead of the bulk of code we had here previously.
Here is the implementation of the above method:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
public static void AddHandlers(this IServiceCollection services)
{
List<Type> handlerTypes = typeof(ICommand<>).Assembly.GetTypes()
.Where(x => x.GetInterfaces().Any(y => IsHandlerInterface(y)))
.Where(x => x.Name.EndsWith("Handler"))
.ToList();
foreach (Type type in handlerTypes)
{
AddHandler(services, type);
}
}
private static void AddHandler(IServiceCollection services, Type type)
{
object[] attributes = type.GetCustomAttributes(false);
List<Type> pipeline = attributes
.Select(x => ToDecorator(x))
.Concat(new[] { type })
.Reverse()
.ToList();
Type interfaceType = type.GetInterfaces().Single(y => IsHandlerInterface(y));
Func<IServiceProvider, object> factory = BuildPipeline(pipeline, interfaceType);
services.AddTransient(interfaceType, factory);
}
private static Func<IServiceProvider, object> BuildPipeline(List<Type> pipeline, Type interfaceType)
{
List<ConstructorInfo> ctors = pipeline
.Select(x =>
{
Type type = x.IsGenericType ? x.MakeGenericType(interfaceType.GenericTypeArguments) : x;
return type.GetConstructors().Single();
})
.ToList();
Func<IServiceProvider, object> func = provider =>
{
object current = null;
foreach (ConstructorInfo ctor in ctors)
{
List<ParameterInfo> parameterInfos = ctor.GetParameters().ToList();
object[] parameters = GetParameters(parameterInfos, current, provider);
current = ctor.Invoke(parameters);
}
return current;
};
return func;
}
private static object[] GetParameters(List<ParameterInfo> parameterInfos, object current, IServiceProvider provider)
{
var result = new object[parameterInfos.Count];
for (int i = 0; i < parameterInfos.Count; i++)
{
result[i] = GetParameter(parameterInfos[i], current, provider);
}
return result;
}
private static object GetParameter(ParameterInfo parameterInfo, object current, IServiceProvider provider)
{
Type parameterType = parameterInfo.ParameterType;
if (IsHandlerInterface(parameterType))
return current;
object service = provider.GetService(parameterType);
if (service != null)
return service;
throw new ArgumentException($"Type {parameterType} not found");
}
private static Type ToDecorator(object attribute)
{
Type type = attribute.GetType();
if (type == typeof(DatabaseRetryAttribute))
return typeof(DatabaseRetryDecorator<,>);
if (type == typeof(AuditLogAttribute))
return typeof(AuditLoggingDecorator<,>);
// other attributes go here
throw new ArgumentException(attribute.ToString());
}
private static bool IsHandlerInterface(Type type)
{
if (!type.IsGenericType)
return false;
Type typeDefinition = type.GetGenericTypeDefinition();
return typeDefinition == typeof(ICommandHandler<,>) || typeDefinition == typeof(IQueryHandler<,>);
}
It might look quite complicated, but don’t worry if you don’t fully understand it. It’s mostly plumbing code, anyway.
just remember to update ToDecorator method that maps attribute to decorators:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private static Type ToDecorator(object attribute)
{
Type type = attribute.GetType();
if (type == typeof(DatabaseRetryAttribute))
return typeof(DatabaseRetryDecorator<,>);
if (type == typeof(AuditLogAttribute))
return typeof(AuditLoggingDecorator<,>);
// other attributes go here
throw new ArgumentException(attribute.ToString());
}
Also, note that there are dependency injection libraries out there that can do such registration for you.
Quick Summary
In the previous section, we streamlined the decorator configuration. Now, to enrich a handler, the only thing we need to do is put decorator attributes on top of it.
All the configuration is now simple and declarative, and also cohesive. Because the handler and its attributes reside close to each other, it’s really easy to see how each of the handlers is configured. No need to refer to the Startup class for that.
Note once again that the ordering of such attributes is important. The decorator whose attribute we put on top will be executed first, the second one after that, and so on, down to the handler itself.
In this particular case, you can see that the database retry decorator goes first and the audit log one goes after it, which means that if we get a database connectivity issue, each of the attempts will be logged separately. This is not what we would like to happen, so we need to re-order the attributes, like this.
1
2
[AuditLog]
[DatabaseRetry]
This way, even with several retries, the handler invocation will be logged only once. And again, although we have introduced our own implementation of the decorators, you can very well use an existing dependency injection library for that, such as, for example, Simple Injector.
Decorators vs. ASP.NET Middleware
At this point, our command and query handlers and the decorators on top of them look a lot like ASP. NET middleware infrastructure.
If you look at the single ASP. NET middleware class we currently have in our project, the ExceptionHandler middleware, and compare it to a decorator of ours, they look very similar, and indeed, they implement the same pattern, the decorator pattern.
ExceptionHandler middleware
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public sealed class ExceptionHandler
{
private readonly RequestDelegate _next;
public ExceptionHandler(RequestDelegate next)
{
_next = next;
}
public async Task Invoke(HttpContext context)
{
try
{
await _next(context);
}
catch (Exception ex)
{
await HandleExceptionAsync(context, ex);
}
}
}
DatabaseRetryDecorator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public sealed class DatabaseRetryDecorator<TCommand, TOutput> : ICommandHandler<TCommand, TOutput>
where TCommand : ICommand<TOutput>
{
public DatabaseRetryDecorator(ICommandHandler<TCommand, TOutput> handler)
{
_handler = handler;
}
public TOutput Handle(TCommand command)
{
for (int i = 0; ; i++)
{
try
{
TOutput result = _handler.Handle(command);
return result;
}
catch (Exception ex)
{
if (i >= 3 || !IsDatabaseException(ex))
throw;
}
}
}
}
The only difference is that the middleware doesn’t rely on explicit interfaces like our ICommandHandler. ASP. NET uses reflection to find a corresponding method to call in the middleware classes, and that is this Invoke method.
Other than that, both of them accept the next item in the pipeline as an input parameter, and both of them put their own logic on top of it.
The middleware class implements the same pattern as our decorator classes, and if we continue the analogy, the controller classes in ASP. NET correspond to our command handlers.
At this point, you might ask, if ASP. NET core in general, and the middleware infrastructure, in particular, are so good, why do we need our own decorators at all? Why not just use what we already have from Microsoft?
And that would be a great question, and indeed, some of the features that people traditionally advised to implement using command handler decorators within the CQRS pattern now can be implemented using plain ASP. NET middleware;
However,
It’s still beneficial to implement some of the cross-cutting functionality using the decorator’s infrastructure we developed.
There are three benefits to this.
-
First, you are getting additional control over how this infrastructure works, and that could be quite helpful at times.
-
Second, this provides the separation of concerns between ASP. NET and your application, which allows you to reason about them independently and therefore with less effort. As a result, such separation of concerns allows you to reduce the maintenance costs of your application.
-
And third, the decorators we’ve developed are easier to apply selectively. The issue with ASP. NET middleware is that it’s hard to tell ASP. NET to which controllers and API endpoints to apply them. You will need to manually analyze the URL of the incoming request and decide whether to apply the middleware logic to it or not. The resulting code is often quite confusing and non-intuitive.
Attributes like those we introduced previously are much easier to work with. As an alternative, you could employ ASP. NET action filters instead of middleware, but they come with a lot of framework-related concerns, which again, don’t help with the separation of concerns between your application logic and ASP. NET wiring.
So, in terms of flexibility and code simplicity, the decorators we’ve developed are a better choice.
Everything that is not ASP. NET-related is best implemented using our own decorators. They are more flexible, they are not bloated with ASP. NET concerns and you have full control over them.
Here are a couple more examples of decorators that you could need to implement.
-
Caching: This would be a decorator on top of IQueryHandler. In our application, it would be useful for caching some of the most used and expensive search queries, and thus offload the pressure from the database.
-
Transaction handling: Currently, we encapsulate the work with both the database connection and database transaction in our UnitOfWork class. We automatically open a transaction when create a repository, but if you would like to execute some of your handlers without a transaction, a separate transaction handling decorator would be helpful here. With it, you can easily mark which of the command handlers you want to execute inside a transaction.
Quick Summary
So far, we discussed how to extend command and query handlers without code duplication and while keeping the handlers themselves simple. For that, we used decorators.
A decorator is a class that modifies the behavior of another class without changing its public interface. In other words, it’s a wrapper that preserves the interface of the thing it wraps. It’s a very powerful technique.
It allows you to introduce cross-cutting concerns to your application without code duplication. It also allows you to adhere to the single responsibility principle, as you can separate the code of the cross-cutting concerns from the code that implements the actual business-use cases.
It’s especially useful because you can chain multiple decorators together, and thus introduce increasingly complex functionality, while still keeping each one of them small and focused on doing only one thing.
You also saw how we streamlined the configuration of the decorators. We implemented our own mechanism for dynamic registration of the decorators. With it, we can mark separate handlers with one or more attributes and thus specify which of them we want to enrich with what functionality. This allowed us to achieve a fantastic degree of flexibility.
We also talked about the similarity between our decorators and the ASP. NET Middleware. They both implement the same decorator pattern. Use ASP. NET middleware for ASP. NET-related functionality. Use the decorators for everything else.
There are three benefits of using hand-written decorators over ASP. NEt middleware. Additional control over your code, separation of the application and ASP. NET concerns, and better flexibility.
All this allowed us to keep the code simple and maintainable, even after we faced more requirements from the stakeholders, such as the database retry behavior and audit logging.
This was one of the three benefits the CQRS pattern provides, code simplicity.
Simplifying the Read Model
Let’s take a look at our Read model. It currently consists of only two queries, GetAllCustomerQuery and GetCustomerQuery. Let’s look into GetAllCustomerQuery:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public sealed class GetAllCustomerQuery : IQuery<Task<Validation<IReadOnlyCollection<Customer>>>>
{
public GetAllCustomerQuery()
{
}
public sealed class GetAllCustomerQueryHandler : IQueryHandler<GetAllCustomerQuery, Task<Validation<IReadOnlyCollection<Customer>>>>
{
private readonly DbContextFactory dbContextFactory;
public GetAllCustomerQueryHandler(DbContextFactory dbContextFactory)
{
this.dbContextFactory = dbContextFactory;
}
public async Task<Validation<IReadOnlyCollection<Customer>>> Handle(GetAllCustomerQuery query)
{
var unitOfWork = new UnitOfWork(dbContextFactory);
var customerRepository = new CustomerRepository(unitOfWork);
var customers = await customerRepository.GetAll();
return Valid(customers);
}
}
}
It asks our application about the customers in the system, and it also provides them with a primary address, or a first address if no primary address is set. this is done at line
1
var customers = await customerRepository.GetAll();
Here, within the GetAll method, we use the IQueryable along with EF to filter the data in.
1
2
3
4
5
6
public async Task<IReadOnlyCollection<Customer>> GetAll()
{
return _unitOfWork.Query<Customer>()
.Include(nameof(Customer.Addresses))
.ToList();
}
This IQueryable is a special interface in .NET that enables data querying. .NET provides extension methods on top of IQueryable, the same extension methods as for IEnumerable, such as, for example, where; but the implementation is very different.
The extension methods on top of IEnumerable work with collections in the local memory. They pretty much just go over the elements in those collections with a simple loop. IQueryable is more complex. It has two properties, a query provider and an expression.
An expression is a type that contains metadata about the request, and the query provider has access to the database and knows how to query it given the above expression. When you work with IQueryable, it doesn’t get executed until you call a method that transforms the IQueryable into an in-memory collection.
Examples of such methods are ToList, Single, First, and so on. In our case, it’s the ToList method that triggers the evaluation of the IQueryable. When we call Query in this line,
1
2
3
return _unitOfWork.Query<Customer>()
.Include(nameof(Customer.Addresses))
.ToList(); //here we transform the IQueryable into an in-memory collection
The support of the IQueryable interface, also known as LINQ, is quite good in such ORMs as NHibernate and Entity Framework.
However, there are some limitations.
For example, You can see that we fetch the customers data along with their addresses. That’s something that LINQ can take care of, but when it comes to filtering the addresses by the primary or first default, the ORM cannot help us with that.
It doesn’t know how to transform such a filtration into a SQL query. That’s why we evaluate the primary address in the view model like this:
1
2
3
4
public AddressDto PrimaryAddress =>
Addresses.FirstOrDefault(a => a.IsPrimary)
?? Addresses.FirstOrDefault()
?? new AddressDto();
This line allows us to filter in-memory objects using the plain LINQ-to-objects provider, which just loops through all those in-memory objects.
As you might guess, because of this limitation, the performance characteristics of the GetAll method is not very good. Because we cannot delegate the filtration to the database, we transfer an excessive amount of data to the application server from the database when we retrieve a not fully filtered set of customers.
The second issue here is the N+1 problem. To complete the filtration in the memory, the ORM needs the rest of the customer data, particularly this addresses collection.
Because this collection is not loaded as part of the customer set, they are loaded lazily one by one. When LINQ iterates through this collection in the memory. All this affects the performance quite badly. It’s not noticeable here, of course, but in applications with high-performance requirements and with large or even moderate amounts of data, that will be a problem.
The second issue is easy to resolve using eager loading which we already did like this
1
2
3
return _unitOfWork.Query<Customer>()
.Include(nameof(Customer.Addresses)) //eager loading
.ToList();
Still, we need to resolve the filtration problem.
Separation of the Domain Model
So, our Read model lacks performance. How can we fix this? Well, that’s what CQRS is all about.
Remember, the core principle of CQRS is to have two models instead of just one. One model for Writes commands, and the other one for Reads queries. And that, in turn, allows you to optimize decisions for different situations.
During the refactoring of our sample project, we have been gradually introducing this separation.
Remember we had a single giant update method at the beginning of this article. We separated it into several task-based API endpoints. That was segregation at the API level.
After that, we introduced further separation when we defined explicit commands and queries and the handlers for them. Thus the split has penetrated the Application Services layer,
But even that is not enough.
We need to go further and introduce the separation at the Domain model level as well. Look at the repository once again.
The GetAll method uses the same Domain model as the command handlers. It uses the same Customer entity, and that puts a restriction on what we can do with this method. As I said previously, LINQ doesn’t provide enough functionality for us to fully utilize our database. The resulting SQL query is not optimal.
So the use of the domain model limits our ability to write high-performant SQL queries. If you look at the Customer model, you can see that we are using the Addresses property, and if you look at the usages of them, this GetAllCustomerQuery handler use this property just to figure out primary address.
So what we have here is unnecessary over-complication of the domain model to fit the needs of the query side of our application.
We cannot utilize highly optimized database queries in such an environment. And that is a perfect illustration of what you usually end up with when trying to fit the Read and Write responsibilities into a single model.
You end up having a more complex domain model that handles neither of those responsibilities well.
The thing is,
There is no need for a domain model within the Read side of the application. The domain model is only required for commands, not queries.
One of the ultimate goals of domain modeling is achieving a high degree of encapsulation, making sure that when you change something in the system, all the data in it remain consistent, and no invariants are broken.
But,
As we don’t change anything on the Read side, there is no need for the encapsulation, and, by extension, no need in the domain modeling, either. The only thing the Read side needs to worry about is how to better present data to the client, and so you can just drop the domain model from the query handlers.
You can get rid of all other abstractions, too. For example, you don’t need an ORM here, either. You can write all the database access code manually, and that would be beneficial in many cases.
Because
You would be able to use the database-specific optimization techniques that you wouldn’t be able to use with a complex ORM, such as NHibernate or Entity Framework. Let’s see how we can do that.
Simplifying the Read Model
Alright, we are going to get rid of the domain model entirely in the Read side of our application. We will no longer be using the repository when querying data from the database.
So,
As we won’t be using the ORM here, we don’t need the EF, either. What we need instead is a direct connection to the database that we’ll be running our SQL queries against. For this, I’m going to use Dapper. It is a light-weight ORM that is perfect for scenarios where you write SQL queries on your own.
All this library does is it maps the results of those SQL queries to your custom types, which is helpful to avoid a lot of boilerplate code. Alright, here is the SQL query we are going to use.
1
2
3
4
5
6
7
8
SELECT Customers.Id, FirstName + ' ' + LastName as Name, Age, Street, City, ZipCode FROM
Customers INNER JOIN Addresses
ON Addresses.Id = (
SELECT TOP 1 Id
FROM Addresses
WHERE CustomerId = Customers.Id
ORDER BY IsPrimary DESC
);
No need to dive deep into it. Just note that this SQL query does everything in one database roundtrip, which greatly increases the performance,
And here is a class that would hold the results of the above query for us.
1
2
3
4
5
6
7
8
9
public class CustomerInfoDto
{
public long Id { get; set; }
public string Name { get; set; }
public int Age { get; set; }
public string Street { get; set; }
public string City { get; set; }
public string ZipCode { get; set; }
}
So, here it is, our new implementation of the GetList query handler.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public sealed class GetAllCustomerQueryHandler : IQueryHandler<GetAllCustomerQuery, Task<Validation<IReadOnlyCollection<CustomerInfoDto>>>>
{
private readonly ConnectionString connectionString;
public GetAllCustomerQueryHandler(ConnectionString connectionString)
{
this.connectionString = connectionString;
}
public async Task<Validation<IReadOnlyCollection<CustomerInfoDto>>> Handle(GetAllCustomerQuery query)
{
string sql = @"
SELECT Customers.Id, FirstName + ' ' + LastName as Name, Age, Street, City, ZipCode FROM
Customers INNER JOIN Addresses
ON Addresses.Id = (
SELECT TOP 1 Id
FROM Addresses
WHERE CustomerId = Customers.Id
ORDER BY IsPrimary DESC
);";
using (SqlConnection connection = new SqlConnection(connectionString.Value))
{
IReadOnlyCollection<CustomerInfoDto> customers = connection
.Query<CustomerInfoDto>(sql)
.ToList();
return Valid(customers);
}
}
}
We can now remove the GetAll method in the repository. Also, we can go to the customer dto, and get rid of this line here.
1
2
3
4
public AddressDto PrimaryAddress =>
Addresses.FirstOrDefault(a => a.IsPrimary)
?? Addresses.FirstOrDefault()
?? new AddressDto();
We have been using them for the sole purpose of filtering the in-memory data for the List query result.
Quick Summary
In the previous example, you saw how we simplified the Read side. It no longer uses the domain model, nor does it use NHibernate. We did the data retrieval manually, using a custom SQL query, and because of that, because we removed all those abstraction layers, our Read model has become just a thin wrapper on top of the database.
On the one hand, it means that we now have to write all our SQL on our own, but on the other, it also means that we are not restricted by the abstraction layers. We can use as many database-specific features as we want, and that allows us to create a highly optimized and performant solution for our specific problem.
Note that it’s not a bad thing that the Read model is now tightly coupled to the database vendor, SQL Server in our case.
The query side has become optimized because we were able to use database-specific features to retrieve only the minimum amount of data, as well as do this in a single database roundtrip.
In other words, the Read model has become a thin wrapper on top of the data storage. This is beneficial because there’s no need for encapsulation here. The Read model doesn’t mutate the data, and thus it cannot violate any invariants in the application.
We have optimized data retrieval. We now select only the minimum amount of data and we do that in just one database roundtrip.
Also, our repositories now have very few methods aside from GetById, Save, and Delete. That’s usually all the domain model needs when you don’t use it in the Read side of the application.
Conclusion
CQRS allows you to separate the load from reads and writes allowing you to scale each independently.
Separating the write model from the read models helps us separating complex aspects of our domain and increase the flexibility of our solution. We can adapt more simply to changing business requirements.
In our sample project, we gradually introduced separation to our system. First, we separated our API endpoints and split the single giant update method into several task-based ones. That allowed us to transition away from the CRUD-based thinking, and introduce a task-based interface, both the UI and the API.
Next, we extracted explicit commands and queries, and handlers for them out of our controller. That allowed us to introduce a unified. NET interface for the handlers, and then create decorators to tackle cross-cutting concerns with the minimal amount of effort.
After that, we extracted the domain model out of the Read side, which allowed us to both simplify the domain model and write high-performance SQL queries for the Read side.
The three benefits of CQRS are simplicity, performance, and scalability. Despite of these benefits, you should be very cautious about using CQRS.
When should I use CQRS?
Although we saw some of the reasons why you might decide to apply the CQRS pattern, it is helpful to have some rules of thumb to help identify the system that might benefit from applying the CQRS pattern.
Consider applying CQRS to limited sections of your system where it will be most valuable. In general, applying the CQRS pattern may provide the most value in those parts of the system that are collaborative, complex, include ever-changing business rules, and deliver a significant competitive advantage to the business.
Collaborative domains
The CQRS pattern is particularly useful where the collaboration involves complex decisions about what the outcome should be when you have multiple actors operating on the same, shared data.
For example, does the rule “last one wins” capture the expected business outcome for your scenario, or do you need something more sophisticated? It’s important to note that actors are not necessarily people; they could be other parts of the system that can operate independently on the same data.
CQRS allows you to define commands with enough granularity to minimize merge conflicts at the domain level, and conflicts that do arise can be merged by the command.
Note: Collaborative behavior is a good indicator that there will be benefits from applying the CQRS pattern; however, this is not a hard and fast rule!
Stale data
In a collaborative environment where multiple users can operate on the same data simultaneously, you will also encounter the issue of stale data; if one user is viewing a piece of data while another user changes it, then the first user’s view of the data is stale.
Whatever architecture you choose, you must address this problem. For example, you can use a particular locking scheme in your database, or define the refresh policy for the cache from which your users read data.
The CQRS pattern helps you address the issue of stale data explicitly at the architecture level. Changes to data happen on the write side, users view data by querying the read side.
Moving to the cloud
Moving an application to the cloud or developing an application for the cloud is not a sufficient reason for choosing to implement the CQRS pattern. However, many of the drivers for using the cloud such as requirements for scalability, elasticity, and agility are also drivers for adopting the CQRS pattern. Furthermore, many of the services typically offered as part of a platform as a service (PaaS) cloud-computing platform are well suited for building the infrastructure for a CQRS implementation: for example, highly scalable data stores, messaging services, and caching services.
When should I avoid CQRS?
This pattern isn’t recommended when the domain or the business rules are simple or where a simple CRUD-style user interface and data access operations are sufficient.
Like any pattern, CQRS is useful in some places, but not in others. Many systems do fit a CRUD mental model, and so should be done in that style. CQRS is a significant mental leap for all concerned, so it shouldn’t be tackled unless the benefit is worth the jump.
Further Reading
Event Sourcing pattern - In this article, you will learn about Event Sourcing pattern. Event Sourcing pattern defines an approach to handling operations on data that’s driven by a sequence of events. Instead of storing just the current state of the data in a domain, Event Sourcing pattern use an append-only store to record the full series of actions taken on that data. The store acts as the system of record and can be used to materialize the domain objects.
Introducing Event Sourcing - Event sourcing (ES) and Command Query Responsibility Segregation (CQRS) are frequently mentioned together. Although neither one necessarily implies the other, you will see that they do complement each other. This chapter introduces the key concepts that underlie event sourcing and provides some pointers on the potential relationship with the CQRS pattern.
Books
Exploring CQRS and Event Sourcing: A journey into high scalability, availability, and maintainability with Windows Azure (Microsoft patterns & practices) - This guide is focused on building highly scalable, highly available, and maintainable applications with the Command & Query Responsibility Segregation and the Event Sourcing architectural patterns. It presents a learning journey, not definitive guidance. It describes the experiences of a development team with no prior CQRS proficiency in building, deploying (to Windows Azure), and maintaining a sample real-world, complex, enterprise system to showcase various CQRS and ES concepts, challenges, and techniques.
Online Courses
-
CQRS in Practice by Vladimir Khorikov - There are a lot of misconceptions around the CQRS pattern. This course is an in-depth guideline into every concern or implementation question you’ve ever had about CQRS.
-
Modern Software Architecture: Domain Models, CQRS, and Event Sourcing by Dino Esposito - This course covers DDD analysis patterns helpful in discovering the top-level architecture of a business domain. Architects and developers will find details of implementation patterns such as Domain Model, CQRS, and Event Sourcing.
Related Videos
- CQRS Secrets: How to Support Scalability and Performance - CQRS is deceptively simple when drawn on a whiteboard, but what happens when you have to turn that picture into code? See how to implement the CQRS pattern in .NET, learn about the design choices you will need to make, and understand how tools like Application Insights can align with CQRS to help you, monitor, diagnose and remediate performance and scalability problems.
Frameworks
- CQRSlite - CQRSlite is a small CQRS and Eventsourcing Framework. It is written in C# and targets .NET 4.5.2 and .NET Core. CQRSlite originated as a CQRS sample project Greg Young and Gaute Magnussen did in the autumn of 2010. CQRSlite has been made with pluggability in mind. So every standard implementation should be interchangeable with a custom one if needed.
References
- https://martinfowler.com/bliki/CQRS.html
- https://martinfowler.com/bliki/CommandQuerySeparation.html
- http://codebetter.com/gregyoung/2010/02/16/cqrs-task-based-uis-event-sourcing-agh/
- http://udidahan.com/2009/12/09/clarified-cqrs/
- https://enterprisecraftsmanship.com/posts/new-online-course-cqrs-in-practice/
Subscribe to Code with Shadman
Get the latest posts delivered right to your inbox